В этом разделе мы рассмотрим подходы к фактическому документированию кода. Существует несколько подходов, которыми пользуются писатели и инженеры, мы познакомимся с пятью из них с примерами и комментариями.
Подход 1: размещаем “Как?” во внутренние комментарии, “Почему?” - во внешней документации.
После прочтения вступления к модулю “Документирование кода” одна из читательниц поделилась своим подходом. Вот, что она написала:
Кажется, такое разделение и расположение комментариев кода имеет место быть. Можно разделять пояснения на две основные категории:
- как?
- почему?
После разделения, пояснения Как? встраиваются в код в виде комментариев (примерно на каждые 5-10 строк). Пояснения Почему? встраиваются во внешних разделах до или после кода. Разумеется, в пояснениях Как? можно получить подробную информацию о Почему? причинах, и наоборот, поэтому разделение этих двух вопросов на практике может быть не таким простым. Но такая общая закономерность, скорее всего, верна.
Кроме того, такой подход интересен тем, что он побуждает подумать над вопросом Почему?. Техническим писателям, документирующим код (который пишут другие), не всегда получается учитывать Почему?.Иногда бывает трудно понять, какие вопросы Почему? существуют. Зачем использовать этот класс вместо другого? Почему так, а не так? Часто существует много разных способов достижения цели, так почему же идти по этому пути, а не каким-то другим?
В общении с разработчиками о примерах кода, стоит задавать это вопрос: Почему?
- существуют другие подходы, от которых они отказались? Почему?
- могут ли пользователи реализовать какой-либо другой подход, или мы специально хотим, чтобы они следовали только одному методу? Почему?
- почему используется именно этот язык / инструмент / рамки / библиотеки, а не какой-либо другой?
Что касается вставки встроенных комментариев, best practice - это лучше всего вставлять короткие комментарии на каждые 5-10 строк кода. Получается не так много комментариев, что сделать код нечитаемым, но не так мало, чтобы не объяснять, что происходит.
Также стоит обратить внимание, что комментарии встроенного кода могут быть несколько спорными. Если просто объяснять, что делает код, это может оказаться лишним для знатока языка, на котором написан код. Как уже говорилось в разделе Исследования о документировании кода, некоторые разработчики считают, что простой код документирует сам себя - его значение понятно тем, кто знает язык, без необходимости объяснения. Но это утверждение про опытных пользователей и не распространяется на сложный код.
Подход 2: сопоставление комментариев в третьей колонке
Лучшие практики для документации в целом (не только для документирования кода) включают размещение полезных инструкций рядом с областью, вызывающей затруднения, что в контексте документирования кода может означать добавление встроенных комментариев, пронизывающих весь код. Но предположим, что нужен большой комментарий о том, что происходит в коде (поскольку уровень сложности не может быть передан в коротком комментарии). Как сопоставить длинную концептуальную / пояснительную информацию с кодом?
Если ваш комментарий больше кода, есть риск сделать код нечитаемым. Если разместить комментарий в разделах, которые идут задолго до или после кода, есть риск создать пропасть между объяснением и кодом, так что читатели не будут знать, к каким частям кода относится объяснение.
Одним из решений такой проблемы размещения документации кода является создание дополнительного третьего столбца в макете. В среднем столбце находится концептуальное объяснение, а в правом столбце - код. Получается, код и его описание сопоставляются таким образом, что читатели могут взглянуть на код, читая концептуальные объяснения. Третий столбец поддерживает необходимый контекст между кодом и объяснениями. Вот пример из Twilio, демонстрирующий этот сопоставленный подход:
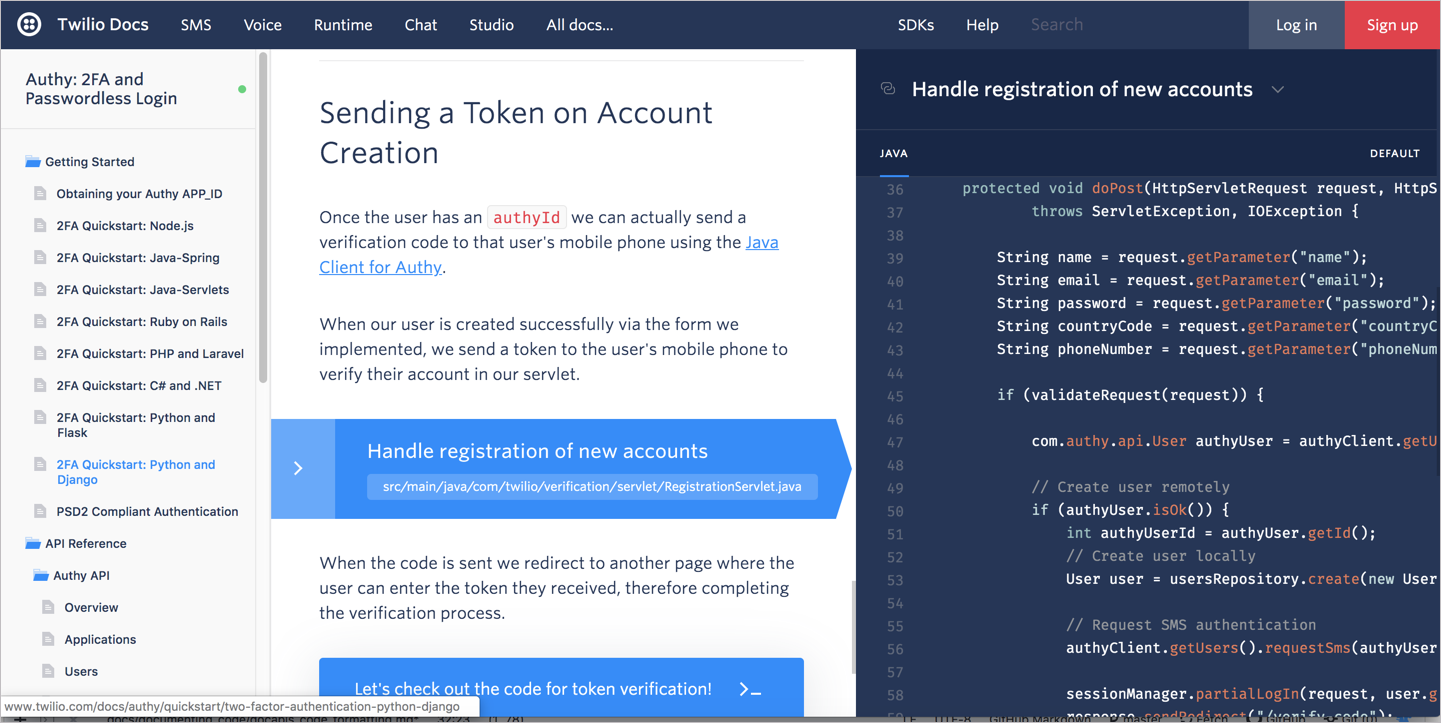
В этом примере концептуальное содержание и шаги появляются в средней колонке, код справа, на темном фоне для создания визуального контраста.
Некоторые экраны Twilio фактически “размывают” нерелевантный код, позволяя сосредоточить свое внимание на линиях, сформулированных в концептуальной области, например:
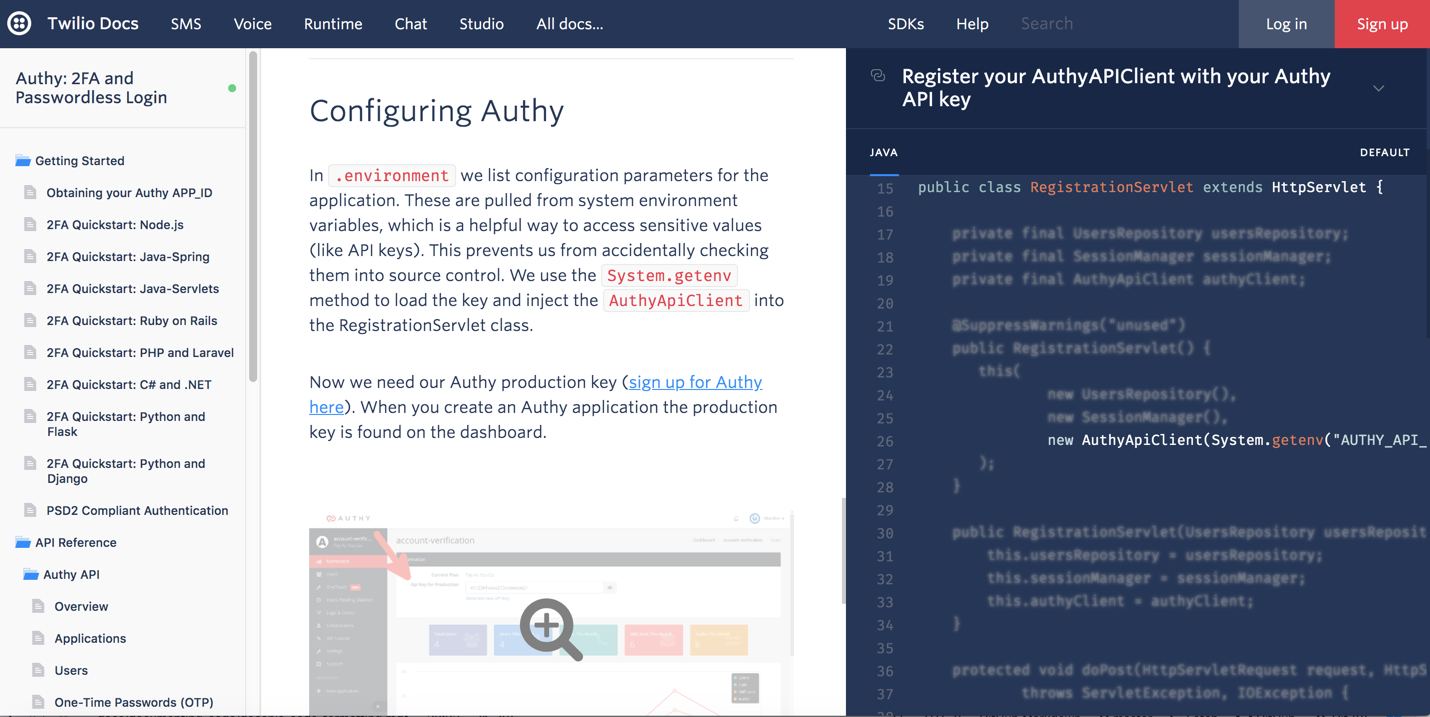
Одной из проблем такого подхода является пространство экрана. Чтобы добавить третью колонку, нужно занять весь экран без полей. (Странно, что в Twilio нет возможности свернуть левую панель навигации, освободив тем самым больше места для кода.)
Таким образом, код виден только частично. Код можно растянуть по горизонтали с возможностью прокрутки вправо, но, несомненно, дизайнерам тяжело дался пользовательский интерфейс, который включает в себя горизонтальную и вертикальную прокрутку.
Вдобавок, реализация размытия фокуса области экрана с кодом, на описании которого находится пользователь, должна быть технически сложной и громоздкой.
Другая проблема заключается в том, что код и пояснения к нему редко можно выровнять линейно. Предположим, есть метод в коде, который занимает всего одну строку, но описание этого метода занимает три длинных параграфа концептуального объяснения. К тому времени, когда пользователь достигает нижней части концептуального объяснения, код уже не виден. Пользователю приходится сделать много лишних манипуляций, чтобы найти соответствующий код. Дизайн пользовательского интерфейса для размещения всех этих движущихся частей не только кажется сложным, но и увеличивает нагрузку на пользователя.
Еще одна проблема, связанная с таким дизайном, заключается в том, что код часто относится к нескольким файлам. Отображение в колонке не указывает, отображается ли весь код в одном и том же файле Java или мы видим код из нескольких файлов Java. Представление вкладок в столбце кода требует еще более сложного формата документации. Сложно представить, что все это возможно сделать с помощью синтаксиса Markdown.
Подход 3: подход Лего
Другой подход заключается в создании кода с нуля, уровня за уровнем, который можно назвать “подходом Лего”. В качестве примера подхода Лего можно посмотреть на пример в eBay Shopping API Поиск по продавцу: Просмотр информации о продавце.
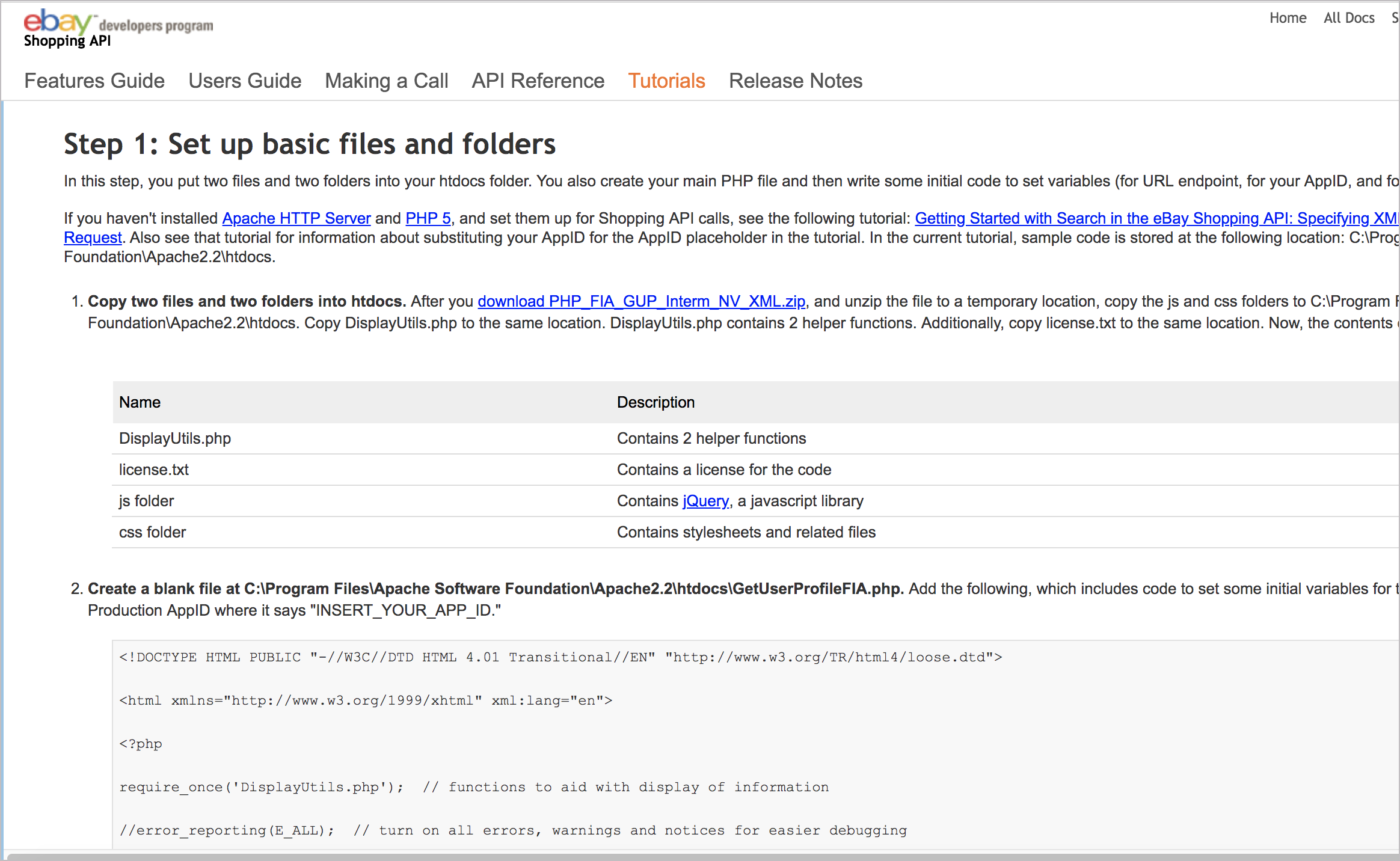
У них в руководстве всего 5 шагов:
- Шаг 2: Добавляем код для вызова GetUserProfile и отображения результатов
- Шаг 3: Добавляем код для вызова FindItemsAdvanced и отображения результатов
- Шаг 4: Добавляем HTML и Javascript для пользовательских интерфейсов
- Шаг 5: Запускаем код
Подход Лего можно начать с пустого файла. Затем с каждым шагом добавлять все больше и больше кода, пока не получится полностью рабочий пример. Как и в случае с конструктором Лего - начинаем с основания, а затем добавляем блок за блоком, пока не получим желаемый результат.
Проблема с подходом Лего заключается в том, что технический писатель вряд ли воссоздаст логику построения, которой следовал разработчик. Скорее всего, разработчики просто отправят готовый кусок кода в документ, и тогда придется получать пояснения от разработчика о коде, как описано в разделе Почему так трудно документировать код?, где описаны основные проблемы.
Поскольку код нелинейный, пошаговая работа с пояснениями кода не обязательно будет соответствовать подходу Лего. Код, отображаемый в верхней части, может показаться разработчикам вишенкой на торте - например, абстрагирование более сложных строк в переменные, которые используются для уменьшения сложности работы кода. Готовый код часто имеет логику, которая абстрагируется в переменные или другие ссылочные функции, так что определенные части конечного кода остаются чище и более краткими, а другие части становятся более непрозрачными. Готовый код часто слишком запутанный и сложный, чтобы документировать его любым доступным для обучения способом.
Несмотря на проблемы с подходом Лего, если нужно научить кого-то, как понимать код, нужно начать с простого и идти шаг за шагом от простого к сложному. Следующая техника объясняет такой подход от простого к сложному при помощи метафоры наутилуса.
Подход 4: подход Наутилус
Подход Наутилус аналогичен подходу Лего, но вместо того, чтобы описывать куски работы, которые выполняются один за другим в порядке сборки, здесь описываются основные простые шаблоны, которые должны знать пользователи. Начинается с самого простого кода, а затем проект увеличиваться и увеличиваться по мере необходимости, как растущая спиральная структура оболочки наутилуса.
Пол Густафсон, управляющий компанией, занимающейся техническим обслуживанием письма, в Bay Area, которая называется Экспертная поддержка, представляет подход с метафорой Наутилуса, описанный здесь. Пол говорит, что наутилус является хорошей метафорой для технической коммуникации, потому что наутилус представляет спиральную схему (последовательность Фибоначчи), которая начинает с малого и постепенно растет по мере необходимости:

Пол пишет:
Когда ваше понимание невелико, вы учитесь лучше, когда первый урок дает информацию для небольшой, простой задачи с чертами, которые сродни первым камерам наутилуса.
… Хорошая новость для наутилуса заключается в том, что маленькие камеры следуют тому же основному плану, что и большие камеры. Если первые задания, которые освоил учащийся, в основном аналогичны более сложным задачам в учебной программе, учащийся начинает понимать и применять эти шаблоны. Чем раньше новички научатся «думать о вещах правильно», тем быстрее они «поймут», а это именно то, чего хотят и преподаватель, и ученик. (Уроки головоногих)
Следуя подходу Наутилус, мы начинаем с простых базовых шаблонов, а затем постепенно наращиваем объем кода вокруг него по мере необходимости. Мы не начинаем с описания сложной законченной работы с самого начала. Законченная работа, вероятно, включает в себя все виды абстракций кода и перестановки для чистого, готового продукта.
Проблема в том, что мы часто хотим объяснить, как работает готовый код, проводя пользователя через все от начала до конца. У нас может быть 500 строк кода, которые мы хотим сформулировать, но подход Nautilus заставил бы нас объяснить только несколько небольших фрагментов этого кода (по крайней мере, для начала). Следовательно, существует проблема типа A-против-Z: мы описываем A (самый простой шаблон ядра), но конечным продуктом является Z. Как именно мы добираемся от A до Z? Как мы придем от простых шаблонов, которые могут занимать 20 строк кода, до чудовищно сложного, законченного кода, который занимает 500 строк?
Для технического писателя, смотрящего на окончательный код, нет ясного понимания того, как разработчик попал туда. Мы часто не можем отделить подобную логику, с которой начинал разработчик, что привело его к этой более сложной цели. Все, что мы видим, это этот сложный конец. Как декомпилировать код, чтобы восстановить логику, с которой разработчик начал? Как понять, что это были за начальные паттерны, которые положили начало всему процессу? Если вы не разрабатывали код и не являетесь разработчиком, то будет практически невозможно восстановить шаблон Наутилуса, стоящий за кодом.
В качестве другой аналогии можно рассмотреть возможность научить рисованию. Предположим, задача - описать готовую картину потенциальному художнику. Вам необходимо описать, как рисовать Мону Лизу:

Чтобы задокументировать процесс создания такой картины, что лучше: начать с верха и идти к низу? Нет, это было бы смешно. Скорее всего, лучше начинать с создания овала головы. Потом, несколько общих набросков для глаз и так далее. Может быть, набросать линии перспективы и другую основную структуру. Никто сразу не приступает к цветам, освещению и теням, верно? То же самое с кодом. Начинаем с основы, а затем прокладываем путь к большему количеству завершающих деталей.
Однако, если вы не художник, как бы вы узнали, как описать процесс создания картины? Вам нужно знать логику художника - с чего начать и как идти к концу. Если вместо этого вы начинаете с конца и пытаетесь вернуться назад, руководство по рисованию, вероятно, будет безумно сложным.
Чтобы проиллюстрировать этот момент более четко, приведем пример кода. Автор курса не инженер, но ему удобно работать с Jekyll и темами, он создал шаблон, который будет принимать экспорт контента из инструмента для создания тикетов (например, JIRA) и отображать его в виде отчета документации на веб-странице.
Финальный шаблон выглядит так:
<div class="sprintDuration">{{page.duration}}</div>
{% assign sprintYamlFile = page.sprint_yaml_file %}
<div class="metaReportInfo" markdown="span">
Tech writers: {% for member in page.team_members %}<a href="https://somesite.company.com/users/{{member}}">{{member}}</a>{% unless forloop.last %}, {% endunless %}{% endfor %}<br/>
Team: <a href="https://ourteamsite.company.com/">DevComm</a><br/>
Sprint: <a href="{{page.sprint_link}}">Link</a>
</div>
<div id="top"></div>
<div class="all-items">
<h2 id="high-level-summary">High-level Summary</h2>
{{page.high_level_summary}}
{% include sprintdisplaylogic.html %}
{% assign sprintYamlFileOpen = page.sprint_yaml_file_open %}
<h2>Open Issues</h2>
<p>ACME project has <b>{{page.open_items_acme}}</b> open issues. Beta project has has <b>{{page.open_items_beta}}</b> open issues.</p>
{% include sprintdisplaylogic_open.html %}
{% include sprintstylesandscripts.html %}
Этот код выглядит как бред, правда. Здесь есть несколько инклюдов, в которых абстрагирована логика, потому что они будут повторяться ее из отчета в отчет. Здесь убраны скрипты и стили, так как они загромождают код, поэтому они хранятся во включаемых файлах.
Представьте, что вы пытаетесь задокументировать этот код. Если бы вы начали сверху и дошли до конца, это было бы настоящим беспорядком. Пользователю также будет трудно читать длинное объяснение. Такой запутанный клубок. И он не распутается, если поспешно собрать все, не задумываясь о чистом, элегантном решении. Нужно было быстро выпустить отчет, поэтому шаблон был взломан как можно быстрее. Разработчики, создающие приложения, часто внедряют подобные хаки и другие костыли, используя скотч и WD-40, как говорит Джоэл Спольски, чтобы получить рабочее решение, поставленное в срок.
Вид завершенного кода, со всеми его быстрыми взломами и нелегкими реализациями, не научит того, кто хочет создать свой собственный шаблон отчета. Вместо этого более полезно начать нуля ос сновным шаблоном. Такой шаблон включает в себя циклический просмотр файла JSON (экспорт тикетов) и извлечение ключевых значений, которые нужно отображать. Эта ключевая логика доступна в sprintdisplaylogic.html, добавленном выше. Вот другое содержание:
{% assign shortIdList = page.short_ids %}
{% for item in shortIdList %}
{% assign sprintItems = site.data.sprints[sprintYamlFile] | where_exp:"entry",
"entry.ShortId contains item" %}
<h2 id="{{item}}">{{item}} Resolved Doc Issues</h2>
{% for entry in sprintItems %}
<div class="entryTitle">{{entry.Title}}</div>
<div class="entryIssueUrl"><a href="{{entry.IssueUrl}}">{{entry.ShortId}}</a></div>
<blockquote>{{entry.Description | markdownify }}</blockquote>
{% endfor %}
<small><a href="#top">↑ Back to top</a></small>
{% endfor %}
Даже этот кусок сбивает с толку, поскольку есть странные вещи с переменными, вставленными в скобки в ссылках на файл YAML.
Чтобы по-настоящему объединить код с основной логикой, разработчики должны начать с этого:
{% assign sprintItems = site.data.sprints.someyamlfile %}
{% for entry in sprintItems %}
* {{entry.Title}}
* {{entry.Description }}
* {{entry.IssueUrl}}
{% endfor %}
Это основная логика отчета. Он использует цикл for для просмотра элементов в файле данных (доступ к которому осуществляется через site.data.sprints.someyamlfile), а затем Jekyll выводит эти значения через теги типа ''. Как только пользователи изучат эти основные шаблоны, они могут расширить их для создания более сложных решений, таких как вставка переменных в цикл, чтобы можно было повторять логику, не дублируя цикл для каждой категории отчета.
Но если не заниматься разработкой кода, будет чрезвычайно сложно точно определить ядро - простую логику, которая является основным шаблоном кода. С чего начинал разработчик? Какова основная модель, чтобы учиться?
Чтобы собрать эту информацию, нужно взять интервью у разработчика. И при общении с разработчиком, нужно понимать его язык и объяснения. В качестве альтернативы можно попросить разработчика описать логику собственного кода с помощью руководства с правильными вопросами. Например, можно спросить:
- какова основная логика ядра, которую пользователь должен знать здесь?
- Какая самая важная строчка во всем этом коде?
- Можете ли вы объяснить детально эту конкретную часть?
Просто предостережение - если задавать разработчикам эти вопросы, они начнут с обширных объяснений на своем жаргоне, станут нетерпеливыми, если не следовать их логике. Если основные понятия совершенно незнакомы, то просто нереально погрузиться в объяснение. Плюс, может быть трудно объяснить код. Иногда забывается, как работает код Jekyll, примерно через час после его написания. Объяснения требуют большой умственной работы разработчиков (такое нежелание подчеркивает, почему они не пишут документацию в первую очередь).
Лучше записывать интервью с разработчиками, что позволит слушать объяснения в замедленном темпе, нажимая стоп и перематывая назад. сколько понадобится. Если инженер упоминает незнакомую концепцию, можно использовать ее в качестве трамплина для собственного обучения. Это даст соответствующий список тем для изучения (вместо того, чтобы следовать какому-либо общему курсу, который никогда не поможет найти конкретный код, который действительно нужно знать). По крайней мере, можно просто сказать, что сказал разработчик из записи - ведь есть в записи все слова и фразы.
Если декомпилировать логику кода до самого простого шаблона, можно встретиться с другой проблемой: где провести черту между тем, что объяснять, а что не объяснять. На это снова почти невозможно ответить без более глубокого понимания своей аудитории, и есть вероятность, что у инженера не будет большего чувства аудитории, чем у технического писателя, поэтому инженер, скорее всего, сделает то же предположение, что часто делают технические писатели - вообразит, что пользователь не слишком отличается от него самого.
Подход 5: Интерактивный браузер
Изучение основных шаблонов смещает документацию в область руководства. С этим типом обучения связан интерактивный браузер, в котором действие сочетается с обучением. Интерфейсы, выполняемые браузером, имеют своей целью помочь пользователям лучше понять результаты входных и выходных данных, чтобы пользователи могли сами убедиться в том, как работает код, используя более практичный для себя подход.
Наиболее распространенный пример интерактивной документации для API - это пользовательский интерфейс Swagger, который я уже подробно описывал в разделах Знакомство со спецификациями OpenAPI и Swagger и демо Swagger UI:
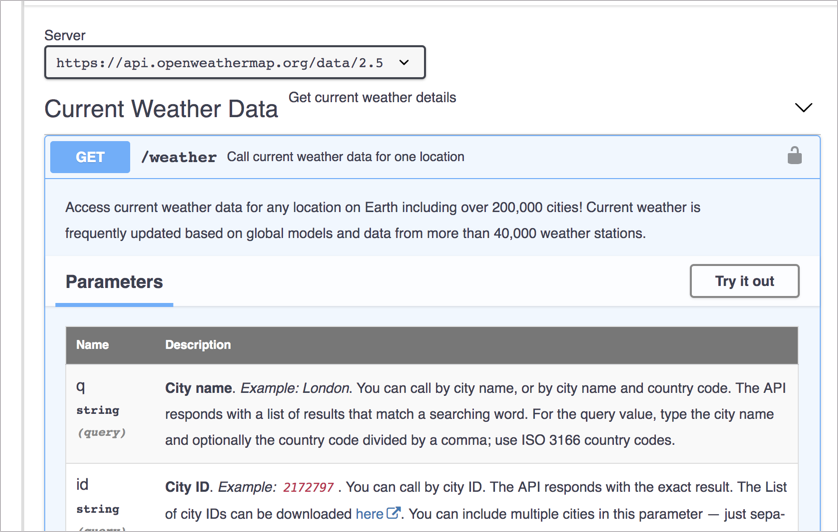
Swagger предлагает оригинальное сочетание документации с активным взаимодействием, которые помогают пользователям изучать API (читая и выполняя). Но выполнение запросов с помощью конечных точек API REST обычно довольно простое. Более интенсивные руководства по коду будет сложнее сделать интерактивными в браузере. Тем не менее, некоторые «Notebooks» (как их часто называют) позволяют запускать код, в частности Jupyter Notebooks. Описание Jupyter:
У Google есть несколько вариантов блокнота для совместной работы с документацией TensorFlow, в которой есть операции, которые можно выполнять на веб-страницах. На следующем скриншоте можно увидеть опцию Run code now:
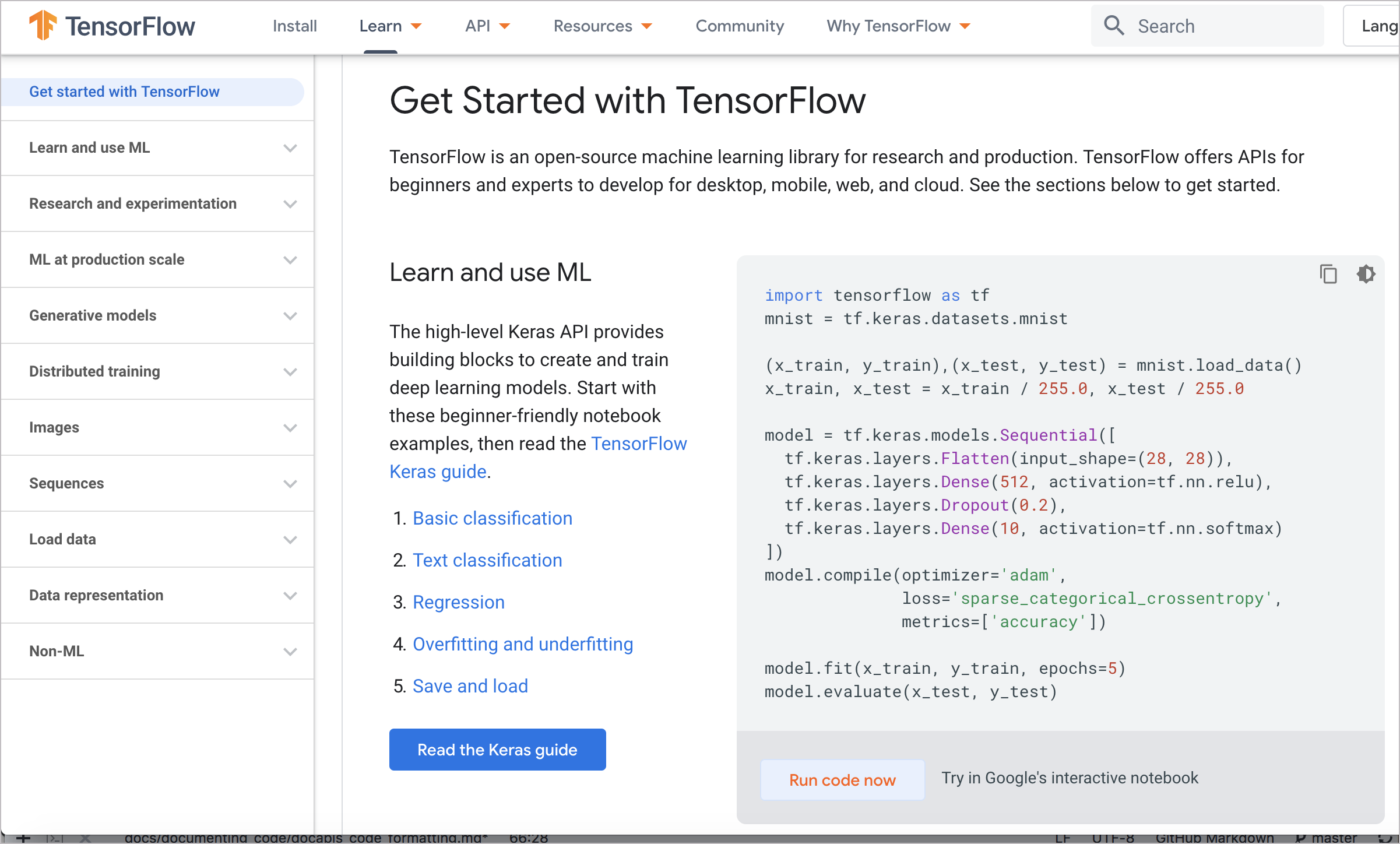
Клик на Run code now открывает интерактивную записную книжку Google, которая фактически запускает код в браузере:
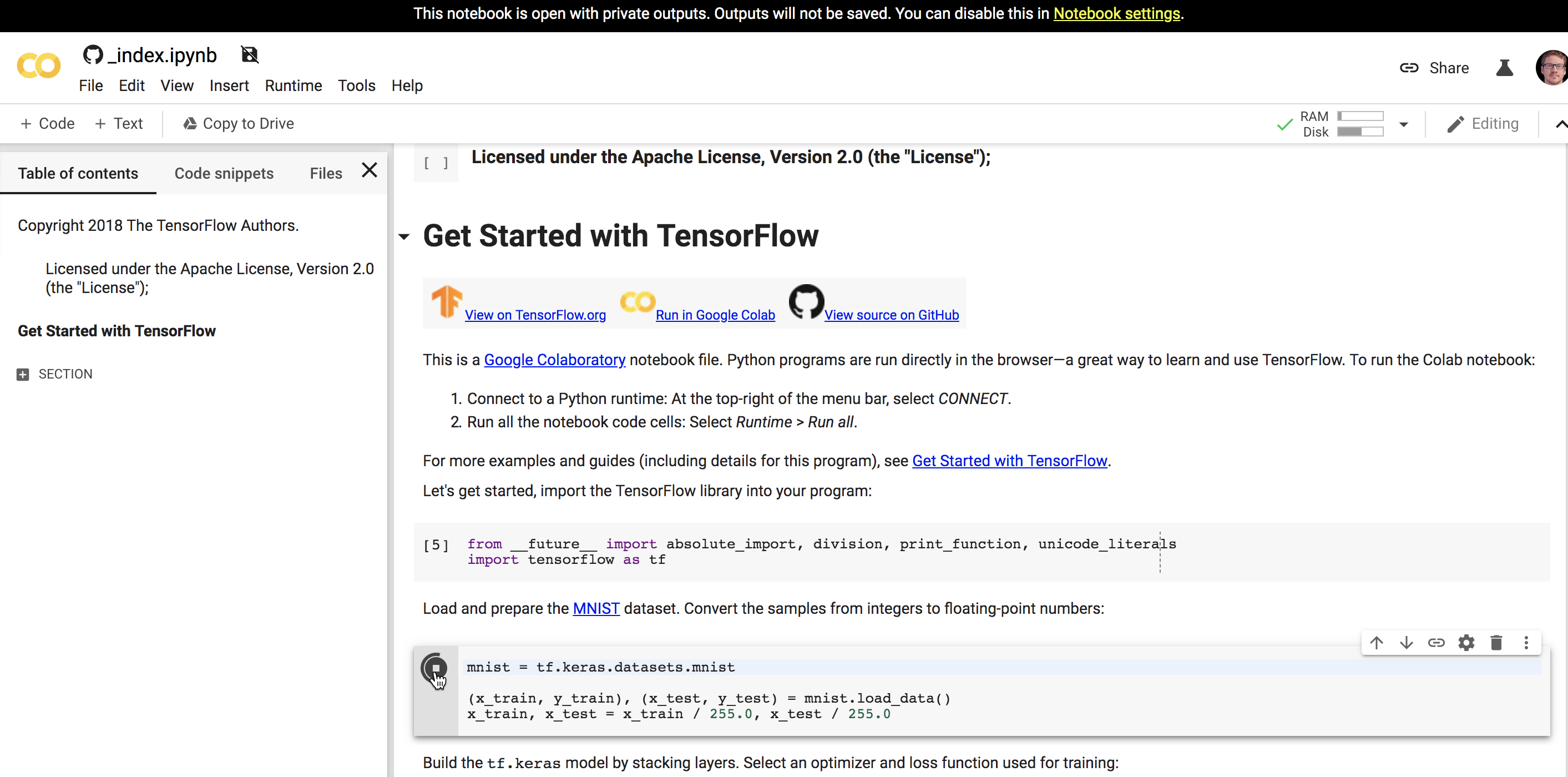
Хотя интерактивные записные книжки выглядят круто, они кажутся огромной работой для чего-то, что может быть легко достигнуто с помощью образца приложения. Вместо того, чтобы выяснить, как вы можете скомпилировать код Python или другой язык в браузере, почему бы просто не предоставить пример приложения, которое пользователи могут загрузить, а затем выполнить локально, используя свои собственные инструменты компиляции и настройки?
Конечно, пользователям может потребоваться установить на своем компьютере некоторые утилиты и платформы, чтобы запустить примеры приложений, а также IDE, но выполнение кода в браузере может информировать не полностью пользователей обо всех необходимых настройках и подготовке, которые в конечном итоге будут быть обязательными для них, чтобы заставить код работать локально. Браузеры имеют тенденцию быть несколько жесткими в том, что они могут сделать - у пользователей может быть больше свободы экспериментировать (и учиться на этих экспериментах) на примерах приложения.
Заключение
В этом разделе мы рассмотрели 5 подходов документирования кода:
- Подход 1: размещаем “Как?” во внутренние комментарии, “Почему?” - во внешней документации.
- Подход 2: сопоставление комментариев в третьей колонке.
- Подход 3: подход Лего.
- Подход 4: подход Наутилус.
- Подход 5: Интерактивный браузер
Лучше использовать подход, который помогает пользователям получить нужные знания для создания собственного кода.
👨💻 Практическое занятие: сравниваем документацию кода с одним из подходов
Ищем раздел с руководством по коду на одном из сайтов документации API, которые изучали. Или посмотрите на один из сайтов документации API в этом посте от Nordic APIs: 5 Примерjd отличной документации API (и почему мы так думаем). В этом посте перечислены пять примеров документации API: Stripe, Twilio, Dropbox, GitHub и Twitter.
И попробуем выяснить, какому подходу лучше всего соответствует документация кода.